
In today’s digital age, where data breaches and privacy concerns are rampant, safeguarding sensitive information is of paramount importance. Organizations face the daunting task of securing their data assets from unauthorized access and malicious attacks. One effective method that has gained significant attention is data masking. In this article, we will explore what data masking is, its importance, techniques, challenges, benefits, best practices, and real-world case studies.
Contents
What is Data Masking?
With the increasing digitization of businesses and the rise in cyber threats, protecting sensitive data has become a critical priority. Data masking, also known as data obfuscation, is a technique that aims to secure sensitive information by transforming it into a realistic but fictitious version while preserving its usability for authorized users.
Data masking is a process that involves substituting or modifying sensitive data elements with fictional, de-identified, or randomized values. The purpose is to prevent unauthorized individuals from accessing sensitive data while maintaining its usefulness for testing, development, and analytics purposes.
Importance of Data Masking
- Protecting Sensitive Data: Data masking ensures that confidential information, such as personally identifiable information (PII) and financial records, remains protected even in non-production environments.
- Compliance with Data Privacy Regulations: Organizations dealing with sensitive data must comply with various data privacy regulations such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). Data masking helps meet these compliance requirements.
- Minimizing Security Risks: By masking sensitive data, organizations can significantly reduce the risk of data breaches, identity theft, and unauthorized access.
- Preserving Data Utility: Data masking techniques maintain the utility of data for development, testing, and analysis purposes, without compromising security.
Techniques of Data Masking
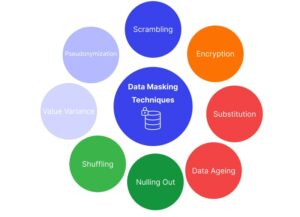
Several techniques can be employed for data masking. Let’s explore some commonly used ones:
Tokenization
Tokenization involves replacing sensitive data with randomly generated tokens. These tokens are used as references to the original data and have no direct relationship to the actual values, making it nearly impossible to reverse-engineer the original information.
Substitution
Substitution replaces sensitive data with fictional, but realistic, data. For example, a person’s real name may be replaced with a randomly generated name that follows the same format and structure.
Shuffling
Shuffling is the process of rearranging the order of sensitive data elements within a dataset. This technique ensures that the original values are preserved but rendered meaningless, as the relationships between data elements are lost.
Encryption
Encryption transforms sensitive data into an unreadable format using cryptographic algorithms. Authorized users can decrypt the data using a secret key. This technique provides an additional layer of security, but it is important to ensure the proper management of encryption keys.
Challenges of Data Masking
While data masking offers significant benefits, it also presents certain challenges that organizations must overcome:
- Data Relationships: Masking sensitive data can lead to challenges in preserving data relationships and maintaining referential integrity.
- Performance Impact: Implementing data masking techniques may introduce additional overhead to data processing and retrieval, potentially impacting system performance.
- Data Consistency: Ensuring consistent masking across multiple systems and databases can be complex, especially when dealing with large volumes of data.
- Data Governance: Proper data governance and management are crucial for maintaining data masking integrity and preventing unauthorized access.
Benefits of Data Masking
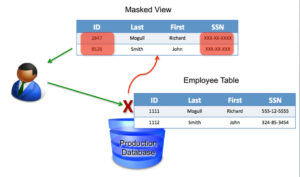
Implementing data masking techniques offers several benefits to organizations:
- Enhanced Data Privacy: Data masking minimizes the risk of exposing sensitive information, ensuring compliance with data privacy regulations and protecting individuals’ privacy.
- Data Security: By obfuscating sensitive data, organizations reduce the likelihood of data breaches and unauthorized access, safeguarding their valuable assets.
- Data Availability for Testing and Development: Data masking allows organizations to use realistic yet de-identified data for testing, development, and training purposes, without compromising security.
- Cost Efficiency: Data masking helps organizations avoid the need for costly physical data segregation by enabling the safe use of production-like data in non-production environments.
Best Practices for Data Masking
To ensure the effective implementation of data masking, organizations should follow these best practices:
- Identify and Classify Sensitive Data: Understand the types of data that need protection and categorize them based on their sensitivity level.
- Data Mapping and Pseudonymization: Create a clear mapping of sensitive data elements and develop a robust pseudonymization strategy to ensure consistent and realistic masking.
- Data Masking Strategy: Define the appropriate data masking techniques based on the sensitivity of the data and the specific requirements of the organization.
- Data Masking Automation: Leverage automation tools and solutions to streamline the data masking process, ensuring accuracy and efficiency.
- Monitoring and Auditing: Implement robust monitoring and auditing mechanisms to track data usage, detect anomalies, and ensure compliance with data privacy regulations.
Case Studies
Let’s explore a few real-world case studies that highlight the effectiveness of data masking:
- Case Study 1: A global financial institution implemented data masking techniques to secure customer data during application development and testing. By ensuring that sensitive data was replaced with fictional values, the organization successfully reduced the risk of data breaches and met compliance requirements.
- Case Study 2: A healthcare provider implemented data masking to protect patient information in non-production environments. This enabled the organization to conduct thorough testing and analysis while safeguarding patient privacy and complying with HIPAA regulations.
Conclusion
In an era where data breaches and privacy concerns are widespread, data masking emerges as a crucial solution to protect sensitive information. By employing techniques like tokenization, substitution, shuffling, and encryption, organizations can secure their data assets while preserving data utility. Implementing data masking best practices ensures efficient and compliant masking processes, benefiting organizations in terms of data privacy, security, and cost-efficiency.
If you are looking to implement any of the Infosec compliance frameworks such as SOC 2 compliance, HIPAA, ISO 27001, and GDPR compliance, Impanix can help. Book a Free consultation call with our experts or email us at [email protected] for inquiries.