
Fault tolerance is a critical aspect of modern systems and infrastructure, ensuring the reliable operation of complex technologies. In today’s interconnected and data-driven world, where downtime can have severe consequences, understanding and implementing fault tolerance measures have become paramount. In this article, we will delve into the concept of fault tolerance, its importance, implementation strategies, real-world examples, challenges, and future trends.
Contents
Understanding Fault Tolerance

Fault tolerance refers to the ability of a system to continue functioning and providing desired services even when one or more components within it fail or experience faults. It is a design principle that aims to ensure system stability, resilience, and continuity in the face of failures or disruptions.
In any system, whether it’s a network infrastructure, a software application, or a complex machinery setup, faults are bound to occur at some point. These faults can range from hardware malfunctions to software bugs, power outages, or even natural disasters. Fault tolerance is essential because it enables systems to maintain their intended functionality, even when subjected to such faults or failures.
Types of Fault Tolerance
Here are some common types of fault tolerance:
- Redundancy: Redundancy involves duplicating critical components or systems to create backups. If one component fails, the redundant component takes over without causing any disruption. Redundancy can be achieved at various levels, including hardware, software, and data.
- Error detection and correction: This type of mechanism involves detecting errors or faults and correcting them in real time. Techniques such as error-checking codes (e.g., checksums and parity bits) and forward error correction (FEC) are used to detect and recover from errors in data transmission or storage.
- Replication: Replication involves creating multiple copies of a system or its components and distributing them across different locations or nodes. Each copy operates independently, and if one copy fails, another can take over seamlessly. Replication is commonly used in distributed systems and databases.
- Failover: Failover is a technique that automatically switches to a backup system or component when a failure is detected. It ensures continuous operation by redirecting traffic or workload to the backup system without interruption. Failover is commonly used in high-availability systems, such as servers or network devices.
- Load balancing: Load balancing distributes the workload across multiple systems or nodes to prevent any single component from becoming overloaded. By spreading the load, load balancing ensures that no individual component is overwhelmed and helps maintain system performance even in the presence of faults.
- Checkpointing: Checkpointing involves periodically saving the state of a system or process. In the event of a failure, the system can be rolled back to a previously saved checkpoint, minimizing data loss and reducing the impact of the failure.
How Fault Tolerance Works?
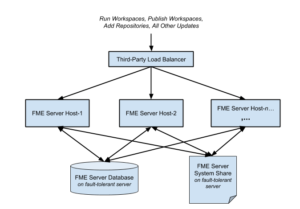
Fault tolerance relies on several key concepts and mechanisms to ensure uninterrupted operation. Let’s explore some of these mechanisms:
Redundancy in Systems
One of the fundamental principles of this tolerance is the incorporation of redundancy in systems. Redundancy involves duplicating critical components or resources, ensuring that some backup systems or elements can seamlessly take over in the event of a failure. By distributing workload or resources across redundant components, the system becomes less susceptible to failures.
Failover Mechanisms
Failover mechanisms play a vital role in this tolerance. These mechanisms automatically detect failures and swiftly transfer the workload or operations to redundant components or backup systems. Failover ensures that the system continues functioning seamlessly without any noticeable disruption to the end users.
Error Detection and Correction
Error detection and correction techniques are essential for maintaining this tolerance. These techniques involve the use of algorithms and protocols that can detect errors, inconsistencies, or discrepancies in the system’s operation. By identifying and isolating faults, error detection mechanisms allow the system to take appropriate actions to mitigate the impact of these faults. Error correction techniques, on the other hand, aim to restore the system to its normal state by rectifying the detected errors.
Benefits of Fault Tolerance
Implementing this tolerance brings several significant benefits to systems and organizations. Let’s explore some of these benefits:
Increased Reliability
Fault-tolerant systems are inherently more reliable than their non-fault-tolerant counterparts. By incorporating redundancy and failover mechanisms, these systems can withstand failures and continue to deliver the expected services. This increased reliability instills confidence in users and stakeholders, establishing trust in the system’s capability to operate seamlessly.
Enhanced Availability
Availability is crucial for systems that need to be accessible and operational around the clock. This ensures high availability by minimizing downtime. When failures occur, the system can quickly switch to redundant components or backup systems, preventing service disruptions and maintaining uninterrupted access.
Minimized Downtime
Downtime can be costly for businesses, resulting in financial losses, reputation damage, and customer dissatisfaction. It plays a critical role in minimizing downtime by swiftly recovering from failures. With failover mechanisms and redundant resources in place, the system can continue its operations seamlessly, reducing the impact of failures on business operations.
Implementing Fault Tolerance

Implementing fault tolerance requires a combination of hardware, software, and network strategies. Let’s explore some of the common approaches to achieving fault tolerance:
Hardware Redundancy
Hardware redundancy involves duplicating critical components, such as servers, storage devices, or networking equipment. Redundant hardware is configured to operate in parallel, ensuring that if one component fails, the redundant component can seamlessly take over the workload. This approach provides high levels of fault tolerance by eliminating single points of failure.
Software Redundancy
Software redundancy focuses on implementing duplicate software components or modules that perform the same functions. These redundant software components are synchronized and work in parallel. If one component fails, the redundant component can take over, ensuring uninterrupted operation. Software redundancy can be achieved through techniques like replication, where data or services are replicated across multiple systems.
Network Redundancy
Network redundancy involves designing networks with multiple paths and alternative routes. Redundant network connections ensure that if one path fails, traffic can be rerouted through alternative paths, maintaining connectivity and preventing disruptions. Network redundancy can be implemented through techniques such as load balancing, link aggregation, and spanning tree protocols.
Real-World Examples of Fault Tolerance
Fault tolerance finds applications in various industries and domains. Let’s explore some real-world examples:
Data Centers
Data centers are critical infrastructures that store and process vast amounts of data for organizations. Fault tolerance is crucial in data centers to ensure continuous operation and data availability. Redundant servers, storage systems, power supplies, and network connections are implemented to eliminate single points of failure and maintain uninterrupted service delivery.
Telecommunication Systems
Telecommunication systems, including mobile networks and internet service providers, rely on fault tolerance to provide uninterrupted connectivity. Redundant equipment, such as switches, routers, and communication links, are deployed to ensure seamless communication even in the presence of failures. Failover mechanisms and network redundancy protocols enable swift recovery and continuous service.
Aviation Industry
In the aviation industry, fault tolerance is of utmost importance to ensure the safety and reliability of aircraft systems. Redundant control systems, sensors, and navigation equipment are employed to provide backup and alternative mechanisms in case of failures. Fault-tolerant designs enable aircraft systems to continue functioning and ensure safe operation even in challenging conditions.
Challenges and Considerations

While fault tolerance offers numerous benefits, there are challenges and considerations to keep in mind when implementing fault tolerance:
Cost and Complexity
Implementing fault tolerance can be costly, as it often requires additional hardware, software licenses, and maintenance. The complexity of configuring and managing redundant systems can also pose challenges. Organizations need to carefully weigh the costs against the potential risks and benefits to determine the optimal level of fault tolerance for their systems.
Scalability and Performance
Increasing fault tolerance can impact system scalability and performance. Redundant components consume additional resources and may introduce overhead. It is crucial to strike a balance between fault tolerance and system performance to ensure efficient utilization of resources while maintaining the desired level of resilience.
Maintenance and Monitoring
Maintaining fault-tolerant systems requires regular monitoring, testing, and maintenance activities. It is essential to proactively identify and address potential issues to prevent failures. Regular updates, patches, and backups are necessary to ensure the effectiveness of fault tolerance measures.
Conclusion
Fault tolerance is a vital concept in modern systems and infrastructure. By incorporating redundancy, failover mechanisms, and error detection and correction techniques, fault-tolerant systems can withstand failures, minimize downtime, and ensure uninterrupted operation. The benefits of fault tolerance include increased reliability, enhanced availability, and minimized disruptions. However, implementing fault tolerance comes with challenges and considerations, such as cost, complexity, scalability, and maintenance. Looking ahead, emerging technologies like AI, cloud computing, and IoT are expected to further enhance fault tolerance capabilities and drive innovation in this field.
If you are looking to implement any of the Infosec compliance frameworks such as SOC 2 compliance, HIPAA, ISO 27001, and GDPR compliance, Impanix can help. Book a Free consultation call with our experts or email us at [email protected] for inquiries.